ESR15 - I/O Optimization using NVRAM as both Memory and Persistent Storage
Recruiting Institution/Company: Cray UK (United Kingdom)
PhD awarded by: University of Bristol (United Kingdom)
PhD Thesis: Abstractions for Portable Data Management in Heterogeneous Memory Systems
Memory systems are becoming increasingly complex and diverse, which complicates the search for optimal data placement and reduces the portability of applications. As we enter the dawn of the exascale era, memory models have to be rethought to consider the new trade-offs between latency, bandwidth, capacity, persistence and accessibility, and their impact on performance. Moreover, this data management needs to be simplified and brought within reach of domain scientists in fields outside of Computer Science. During the course of the EXPERTISE project, I studied the question of data selection and placement in heterogeneous memories in modern high-performance computer architectures.
To address this issue, I focused on studying data movement, data optimisation and memory management in systems with heterogeneous memory.
Firstly, a new algorithm was developed that improves the computation of data exchange in the context of multigrid data redistribution. The Adjacent Shifting of PEriodic Node data (ASPEN) algorithm that resulted from this work provides better performance than state-of-the-art algorithms used for producer-consumer data redistribution of block-cyclic organised data, as used in distributed numerical applications and libraries (e.g. ScaLAPACK).
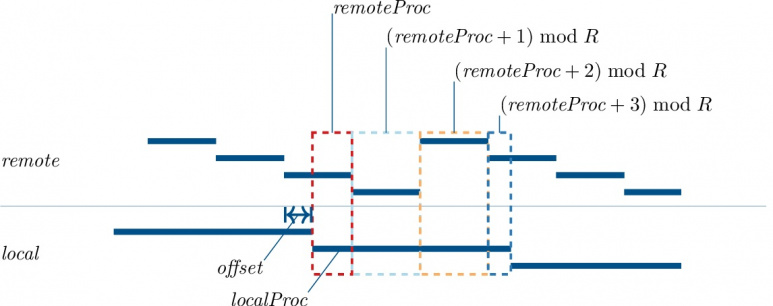
Offset is a periodic difference that will mean a local-remote comparison is valid for this local block when offset is greater than a threshold.The leftmost part of local data maps to processor remoteProc. Adjacent data on the local processor can be known to then map to remoteProc+1 (and repeated for any further adjacent blocks); R represents the remote grid size in the considered dimension.
Secondly, multiple APIs for memory management were unified into a single abstraction that provides memory allocations and transfers in the form of a portable, adaptive and modular library. The Mamba library was developed and aims to facilitate data management on heterogeneous memory systems. It uses a data broker developed with library cooperation and interoperability in mind. In addition to providing portability and memory abstraction, it also serves as a comparison tool for benchmarking or exploratory experiments.
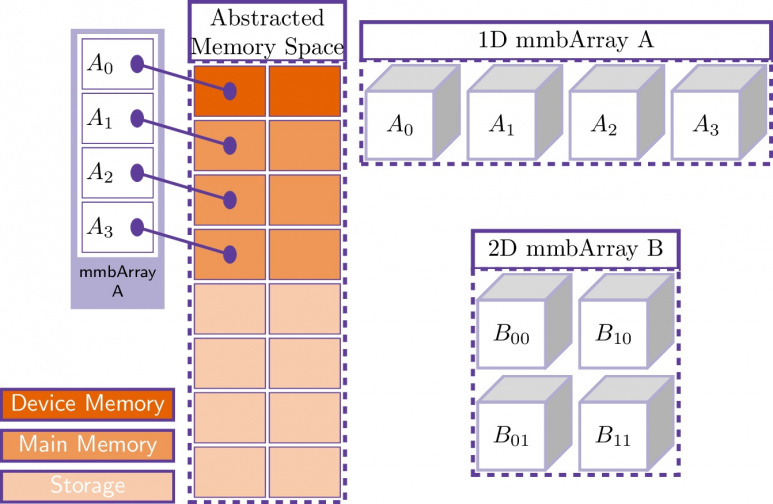
Illustration of the concept of tiled Mamba Arrays, where each tile may reside in a different memory space as defined by the Mamba memory system model
Lastly, the allocation management was studied in a high-level language along with ways to enable low-level control over memory placement for a high-level language. To this end, a use case of memory management (system-wide memory sharing) in C for a Python application has been studied as a proof-of-concept for providing direct memory management to high-level application development. It was based on the PyCOMPSS task-based distributed framework and it was part of a collaboration with the Barcelona Supercomputing Center (BSC). The results was an extension to the pre-existing decorators allowing hand-picked selection of read-only arrays to be shared in memory in order to improve the overall application’s performance.
Overall, the project followed a data-centric approach to the challenges heterogeneous memory creates for performance-seeking applications.