ESR12 - Offloading I/O from task-based programming models
Recruiting Institution/Company: Barcelona Supercomputing Center (Spain)
PhD awarded by: Universitat Politecnica de Catalunya (Spain)
Our work within the Expertise project contributes to the efforts of optimizing I/O intensive applications by introducing programming model abstractions
that improve applications I/O performance to achieve total overall performance enhancement. Such performance improvement is achieved in a completely transparent manner.
The next paragraphs summarize the research lines that were undertaken:
First, we enable I/O awareness in task-based programming models. I/O Awareness separates the handling of I/O from computation. I/O awareness
is realized through the concept of I/O tasks that can overlap with compute tasks execution. In addition to addressing I/O congestion. We address I/O
congestion by providing a mechanism for automatically tuning task constraints based on execution time metrics.
Figure 1 illustrates that using the auto constraints (in green), performance improvement can reach up to 40% compared to the baseline experiment (in red).
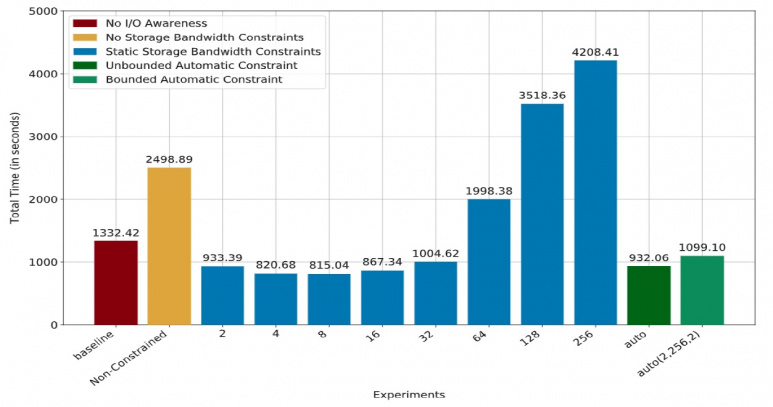
Figure 1
More details about I/O Awareness can be found in our published article:
Towards Enabling I/O Awareness in Task-based Programming Models, Elshazly et al., The Journal of Future Generation Computing Systems (FCGS).
Second, we enable Storage Heterogeneity-Awareness in task-based programming models. Such an approach is able to take advantage of the
heterogeneity of modern storage systems to improve I/O performance. The set of capabilities that a storage-heterogeneity aware programming model
supports include: (i) transparently expose the underlying storage devices as a hierarchical pooled resource such that the top layer has the highest storage bandwidth whereas the bottom layer has the lowest storage bandwidth, also (ii) dedicated I/O schedulers to take advantage of this storage devices organization to increase I/O task parallelism while avoiding I/O congestion, and finally (iii) we present an automatic data flushing mechanism to maximize the usage of higher storage layers.
Figure 2 illustrates that using the I/O schedulers (First Come First Served -FCFS-, Priority, Backfilling) can achieve significant performance improvements in both I/O time and total time, compared to the baseline experiment.
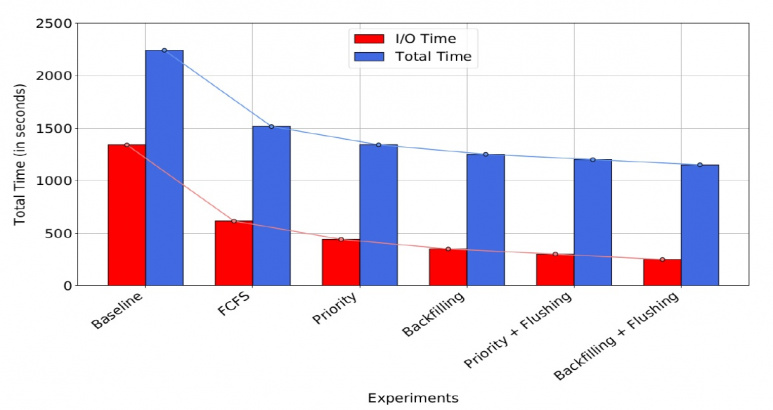
Figure 2
Third, we introduce a hybrid programming model that combines task-based programming models and MPI. This hybrid model allows the execution of tasks on distributed platforms, while using MPI to parallelize tasks execution. This goal is achieved by extending the task-based programming model to support Native MPI Tasks. Such tasks are native in a twofold meaning: From the one hand, the same application source code can have different Native MPI tasks (each with its own number of MPI processes) and different sequential tasks. On the other hand, the code inside Native MPI Tasks can use all shared and global data structures and loaded libraries of the main source file. Such a hybrid programming model is responsible for managing tasks execution and also the interaction between different types of tasks in terms of data transfer, etc.
Figure 3 shows that using Native MPI tasks to parallelize the execution of critical parts of applications can positively impact the total time of applications as the number of MPI processes per task increases.
More details can be found in our published paper:
Performance Meets Programmability:Enabling Native Python MPI Tasks in PyCOMPSs, Elshazly et al., PDP.
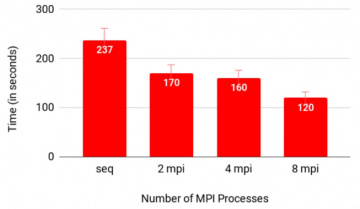
Figure 3
Finally, we introduce a methodology and implementation of an eager-approach for releasing the data dependencies in task-based programming models. Using this approach, successor tasks are launched for execution as soon as their data requirements are generated by the predecessor task(s), without having to wait for the predecessor task(s) execution to completely finish. Such a behaviour enhances execution by allowing the overlapping of tasks execution. For instance, overlapping I/O with computation.
Figure 4 depicts the performance improvement that is achieved when using a programming model that eagerly releases data dependencies compared to a traditional dependencies release approach. The performance improvement in Figure 4 can be explained due to the overlapped execution between I/O and computation; compute tasks are released as the I/O reading task is still reading the data.
More details can be found in our published article:
Accelerated Execution Via The Eager-Release Of Dependencies in Task-based Workflows, Elshazly et al., The International Journal of Higher Performance Computing Applications (IJHPCA).
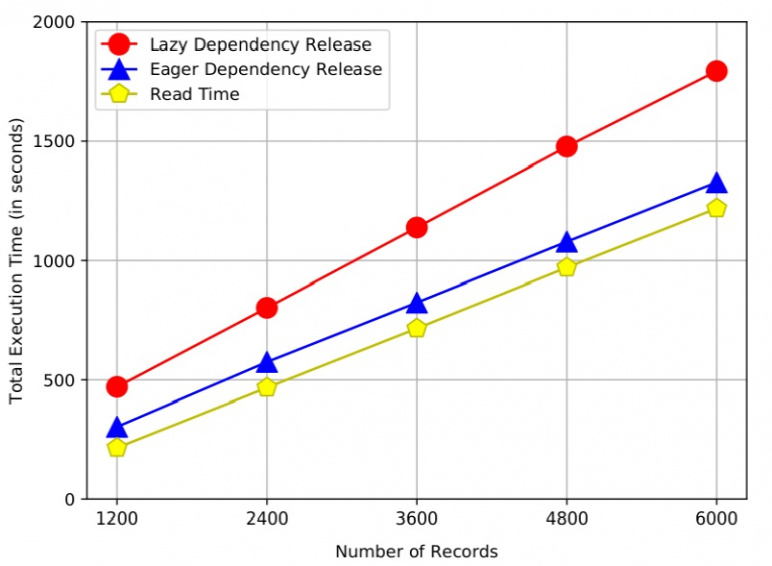
Figure 4.