ESR14 - Offloading of collective I/O tasks in Message Passing Models
Recruiting Institution/Company: Universitaet Stuttgart (Germany)
PhD awarded by: Universitaet Stuttgart (Germany)
Data-intensive scientific applications running on high performance computing (HPC) systems are correspondingly bottlenecked by the time it takes to perform input and output (I/O) of data from/to the file system. Some applications spend most of their total execution times in I/O. This causes a huge
slowdown and wastage of useful compute resources. Thus, I/O becomes probably the most limiting factor for HPC applications.
Parallel I/O is an essential part of scientific applications running on high performance computing systems. Typically, parallel I/O stacks offer many parameters that need to be tuned to achieve the best possible I/O performance. Unfortunately, there is no default best configuration of parameters; in practice, these differ not only between systems but often also from one application use-case to the other. However, scientific users often do not have the time nor the experience to explore the parameter space sensibly and choose the proper configuration for each application use-case.
This study proposes an auto-tuning approach based on predictive modeling, which can find a good set of I/O parameter values on a given system and application use-case. We demonstrate the feasibility to auto-tune parameters related to the Lustre file system and the MPI-IO ROMIO library transparently to the user. In particular, the model predicts for a given I/O pattern the best configuration from a history of
I/O usages.
In auto-tuning, a na¨ıve strategy is to run an application using all possible combinations of tunable parameters to find the best. This is an exhaustive search through the huge parameter space and is infeasible because of the long execution times of trial runs. This becomes a highly time and resource-consuming approach depending on the size of the parameter space. Rather than this approach, we propose an I/O performance predictive modeling based auto-tuning approach. Instead of running the application, we use predictions of IO Predictor as the objective function. This approach can be applied with negligible effort in less execution time.
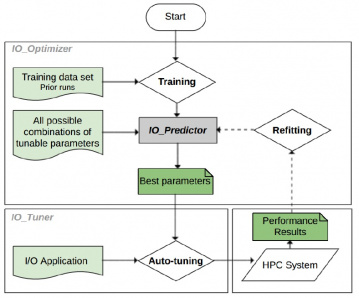
Fig. 1. Overall architecture of performance modeling-based I/O auto-tuning.
Figure 1 shows the overall architecture of I/O autotuning. We first get performance data (training data) for a variety of workloads/parameters, then we build a model IO Predictor in optimization module IO Optimizer. Next, application characteristics are determined at runtime through the PMPI wrapper. Then, we evaluate the model to get the best configuration. All possible combinations of tunable parameters are given to IO Predictor as input. It predicts the I/O performance of all these configuration sets by using a random forest regression method. Then, it sorts the predictions and selects the best-performing parameters among the measured performances for the given application and scale. The tuning module IO Tuner takes the best parameters suggested by IO Predictor and dynamically passes them to the MPI-IO routines of the application or benchmark in the PMPI wrapper. After executing I/O operations, performance results are used to refit IO Predictor with the dynamic conditions of a parallel I/O system adaptively.
We have validated the model with two I/O benchmarks, namely IOR and MPI-Tile-IO, and a real Molecular Dynamics code, namely ls1 Mardyn. We achieve an increase of I/O performance by a factor of up to 18 over the default parameters for collective I/O in the IOR and a factor of up to 5 for
the non-contiguous I/O in the MPI-Tile-IO. Finally, we obtain an improvement of check-point writing time over the default parameters of up to 32 in ls1 Mardyn.